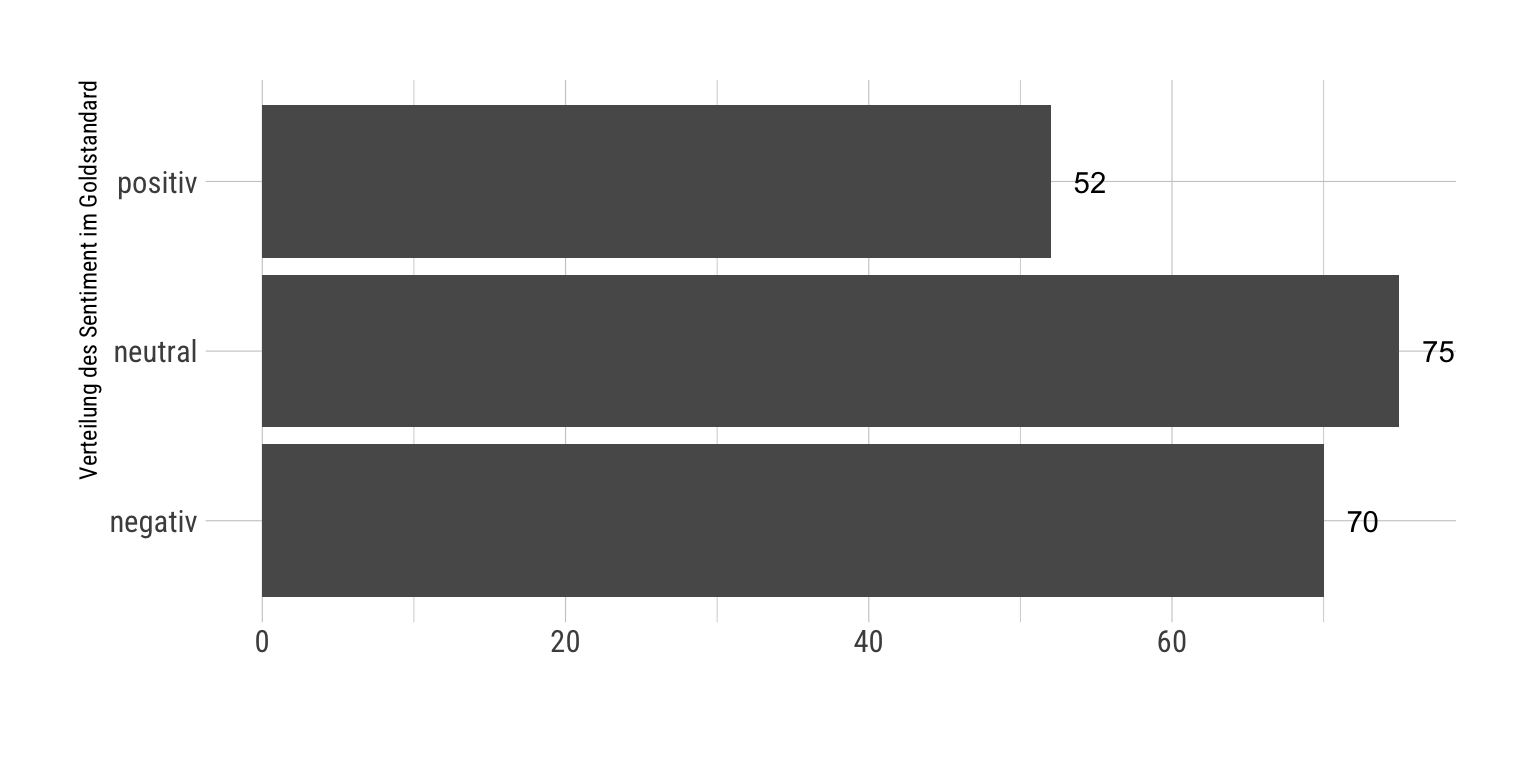Um die Leistungsfähigkeit der LLM-basierten Verfahren zu ermitteln, muss zunächst ein Goldstandard codiert werden. In der Beispielstudie wurde hierzu eine Zufallsstichprobe von 197 Beiträgen des gesamten Datenmaterials (N = 3.054) gezogen. Um eine ausgewogene Stichprobe zu generieren, erfolgte die Stichprobenziehung proportional geschichtet hinsichtlich der Textsorte (n = 60 Zeitungsartikel, n = 71 Facebook-Post, n = 66 Tweets) und disproportional geschichtet hinsichtlich der Tonalität (⅓ jeweils positiv, negativ und neutral, Einstufung auf Basis der Codierung von Spatzenegger, 2020). Die Tonalität aller 197 Texte wurde von drei Codierer*innen auf Grundlage des Codebuchs von Spatzenegger (2020) erfasst. Die Reliabilität des Goldstandards ist für die Validierung von AIA-Verfahren entscheidend (Song et al., 2020); zu ihrer Sicherung bieten sich verschiedene Maßnahmen an (Krippendorff, 2004). Im Beispiel wurde die Reliabilität durch drei Schritte gesichert:
Erstens fanden zwei umfangreiche Codierer*innenschulungen inkl. Probecodierung (je n = 18 Texte) statt. Zweitens wurde das von Spatzenegger (2020) entwickelte Codebuch überarbeitet1. Insbesondere wurden weitere Codieranweisungen aufgenommen und die ursprünglich fünfstufige Tonalitätsskala (1 = sehr positiv, 2 = eher positiv, 3 = neutral, 4 = eher negativ, 5 = sehr negativ) im Sinne einer Vereinfachung in eine dreistufige Skala überführt (1 = negativ, 2 = neutral, 3 = positiv)2. Die Codierung des Goldstandards erfolgte auf Basis der dreistufigen Skala und die Daten von Spatzenegger (2020) wurden für alle folgenden Schritte auf eine dreistufige Skala recodiert (Zusammenfassen der beiden positiven bzw. negativen Ausprägungen zu je einer Ausprägung). Drittens erfolgte eine Mehrfachcodierung: Alle drei Codierer*innen erfassten die Tonalität der 197 Texte unabhängig voneinander. Sie erreichten dabei eine akzeptable Reliabilität von Krippendorff’s a = .77. Bei Abweichungen wurde die Mehrheitsmeinung gebildet, wie von Krippendorff (2004, S. 219) empfohlen.
Goldstandard ansehen
Schauen wir uns zunächst eine kleine Auswahl des Goldstandards an, um ein Gefühl für die Texte zu bekommen. Wir setzen einen Seed, um die Auswahl reproduzierbar zu machen. Durch die Verwendung dieses Seeds können wir auf den folgenden Seiten die gleichen Texte für jedes Modell ansehen, um die Ergebnisse zu vergleichen.
# A tibble: 5 × 3
sentiment_gs textart text
<dbl> <chr> <chr>
1 1 Zeitungsartikel Offline "Dachau Dachau 10000 Kilometer für den g…
2 -1 Zeitungsartikel Offline "Inland Bundesland, Niederösterreich Sei…
3 1 Zeitungsartikel Online "Beate Meinl-Reisinger freut sich über N…
4 1 Tweet "Herzliche Gratulation an Renate Anderl …
5 1 Facebook-Post "Wir möchten Pionier in Europa sein! Mit…
Schauen wir uns außerdem die Verteilung des Sentiments im Goldstandard an. Wir unterscheiden dabei zwischen negativ, neutral und positiv.
Code
R
goldstandard |>mutate(sentiment_gs =case_when( sentiment_gs ==-1~"negativ", sentiment_gs ==0~"neutral", sentiment_gs ==1~"positiv" ) ) |>ggplot(aes(y = sentiment_gs)) +geom_bar() +geom_text(stat ="count", aes(label =after_stat(count)), hjust =-.7) +labs(x ="", y ="Verteilung des Sentiment im Goldstandard")
Das gesamte Material des Goldstandards wurde anschließend mittels (1) eines kategoriespezifischen off-the-shelf-Encoder-Modells, (2) eines aufgabenspezifischen off-the-shelf-Encoder-Modells, (3) eines universellen off-the-shelf-Decoder-Modells, (4) eines off-the-shelf-Diktionärs und (5) zweier klassischer überwachter maschineller Lernalgorithmen codiert. Zur besseren Vergleichbarkeit wurden die Ergebnisse aller Verfahren jeweils in eine dreistufige Skala von -1 (negativ), 0 (neutral) und 1 (positiv) umgewandelt. Die jeweiligen Verfahren werden in den folgenden Kapiteln ausführlich beschrieben.
Literatur
Krippendorff, K. (2004). Content Analysis: An Introduction to Its Methodology (2nd edition). Sage Publ.
Song, H., Tolochko, P., Eberl, J.-M., Eisele, O., Greussing, E., Heidenreich, T., Lind, F., Galyga, S., & Boomgaarden, H. G. (2020). In Validations We Trust? The Impact of Imperfect Human Annotations as a Gold Standard on the Quality of Validation of Automated Content Analysis. Political Communication, 37(4), 550–572. https://doi.org/10/ggnh69
Spatzenegger, A. (2020). Social Media als Quelle journalistischer Arbeit. Journalistik, 3(3), 197–215. https://doi.org/10/g8336z
Die verringerte Anzahl an Ausprägungen fördert die Reliabilität, hatte aber auch technische Gründe: Spatzenegger (2020) hatte in Facebook-Posts und Tweets auch Emojis codiert und diesen die Extremwerte der Tonalitätsskala zugewiesen (1 = sehr positiv und 5 = sehr negativ). Aufgrund von technischen Problemen bei der Speicherung der Originaldaten konnten die Emojis bei der Codierung des Goldstandards nicht reproduziert werden.↩︎