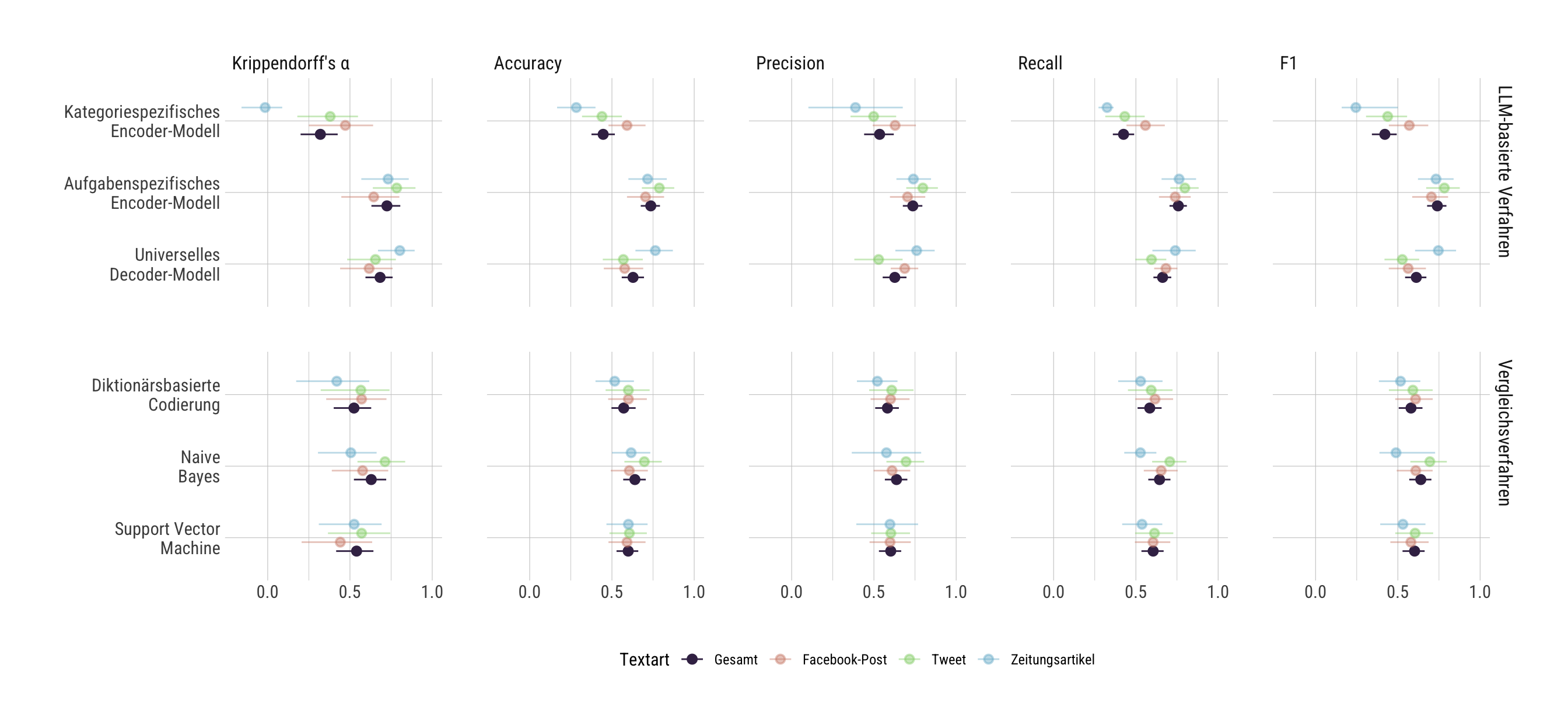
Zur Beurteilung der Leistungsfähigkeit (Prüfung der Validität) oder zur Kontrastierung mit anderen Verfahren (Vergleich) müssen die Codierergebnisse mit dem Goldstandard verglichen werden. Verschiedene Validitätsmaße können hierfür herangezogen werden: Accuracy gibt den Prozentsatz der Übereinstimmung zwischen dem Goldstandard und der jeweiligen Codierung an (vgl. Scharkow, 2012, S. 136). Krippendorff’s α berücksichtigt zusätzlich, wie viele Übereinstimmungen durch Zufall zustande gekommen wären (vgl. Krippendorff, 2004b, S. 414–415). Precision, Recall und F1 beziehen sich jeweils auf die einzelnen Ausprägungen (d. h., “positiv”, “negativ” oder “neutral”) und wurden hier makro-gemittelt, d. h., Precision, Recall und F1 wurden jeweils über alle drei Ausprägungen hinweg gemittelt, ohne Berücksichtigung der Häufigkeit der Ausprägungen. Precision gibt an, welcher Anteil der Texte, die vom Verfahren einer bestimmten Ausprägung zugeordnet wurden, diese Ausprägung tatsächlich laut Goldstandard aufweisen (d. h., wie ‘sauber’ die Codierungen sind, Scharkow, 2012, S. 136). Recall gibt an, welcher Anteil der Texte, die laut Goldstandard eine spezifische Ausprägung aufweisen, erkannt wurde (d. h., wie ‘vollständig’ die Codierungen sind, Scharkow, 2012). F1 ist das harmonische Mittel aus Precision und Recall (Scharkow, 2012).
Einlesen der Daten
Zunächst werden die Daten eingelesen und in ein einheitliches Format gebracht.
Import der notwendigen Bibliotheken für Datenverarbeitung, Visualisierung, Validierungsmetriken, Bootstrap-Sampling und Inter-Coder-Reliabilität.
2
Laden des Goldstandards und Konvertierung der numerischen Sentiment-Werte zu kategorialen Labels sowie Vereinheitlichung der Textarten.
3
Laden der kategoriespezifischen Encoder-Modell Ergebnisse und Konvertierung der Label-Namen zu einheitlichen deutschen Kategorien.
4
Laden der aufgabenspezifischen Encoder-Modell Ergebnisse und Bestimmung der vorhergesagten Kategorie basierend auf den höchsten Wahrscheinlichkeitswerten.
5
Laden der universellen Decoder-Modell Ergebnisse (bereits in korrektem Format).
6
Laden der diktionärbasierten Codierung und Konvertierung der numerischen Werte zu kategorialen Labels.
7
Laden aller maschinellen Lernergebnisse (Facebook, Twitter, Zeitungsartikel), Zusammenführung und Konvertierung der numerischen Werte zu kategorialen Labels für beide ML-Methoden.
8
Zusammenführung aller Datensätze zu einem Validierungsdatensatz und Konvertierung aller Variablen zu Faktoren.
Validierung der Codierergebnisse
Anschließend werden die Validierungsmetriken für alle Verfahren berechnet. Dazu gehören Accuracy, Recall, Precision, F1-Score und Krippendorff’s Alpha. Die Metriken werden mittels Bootstrap-Sampling mit 2000 Wiederholungen geschätzt, um robuste Punktschätzer und 95%-Konfidenzintervalle zu erhalten. Dies wird für den gesamten Datensatz sowie separat für Facebook-Posts, Tweets und Zeitungsartikel durchgeführt.
Definition einer Hilfsfunktion zur Berechnung von Validierungsmetriken: Berechnung von Accuracy, Recall, Precision, F1-Score und Krippendorff’s Alpha für eine gegebene Variable gegen den Goldstandard.
2
Definition einer Bootstrap-Funktion für robuste Schätzung der Validierungsmetriken: Durchführung von Bootstrap-Sampling, Berechnung der Metriken für jede Stichprobe und alle Methoden, sowie Bestimmung von Punktschätzern und Konfidenzintervallen.
3
Bootstrap-Validierung für den gesamten Datensatz: Prüfung auf Existenz der Datei, falls nicht vorhanden Bootstrap mit 2000 Wiederholungen und Speicherung.
4
Bootstrap-Validierung spezifisch für Facebook-Posts: Filterung nach Facebook-Posts und separate Bootstrap-Validierung.
5
Bootstrap-Validierung spezifisch für Tweets: Filterung nach Tweets und separate Bootstrap-Validierung.
6
Bootstrap-Validierung spezifisch für Zeitungsartikel: Filterung nach Zeitungsartikeln und separate Bootstrap-Validierung.
Plot
Zuletzt wird ein Plot erstellt, der die Validierungsmetriken für alle Verfahren und Textarten visualisiert.
Vorbereitung der Plot-Daten: Laden aller Validierungsmetriken für verschiedene Textarten, Umbenennung der Methoden zu lesbaren Labels, Faktorisierung für richtige Reihenfolge und Kategorisierung in LLM-basierte vs. Vergleichsverfahren.
2
Erstellung des Validierungs-Plots: Umstrukturierung der Daten für ggplot, Umbenennung der Metriken, Erstellung eines Point-Range-Plots mit Konfidenzintervallen, farbkodiert nach Textarten und facettiert nach Verfahrenstyp und Metriken.
Die Abbildung illustriert die Prüfung der Validität sowie den Methodenvergleich hinsichtlich der beispielhaft gewählten AIA-Verfahren. Im Hinblick auf die Validität der drei LLM-basierten Verfahren ließe sich in diesem Beispiel eine gemischte Bilanz ziehen: Die Übereinstimmungen der Modell-Codierungen mit dem Goldstandard lagen auf moderatem Niveau, unterschritten aber in einigen Fällen den kritischen Grenzwert von Krippendorff’s α = .667 (vgl. Krippendorff, 2004a, S. 242). Die per Bootstrapping berechneten 95-%-Konfidenzintervalle (2.000 Bootstrap-Resamples) legen nahe, dass sich die Kennwerte größtenteils nicht signifikant zwischen den Modellen unterscheiden, vermutlich aufgrund der geringen Stichprobengröße. Allerdings erreichte das kategoriespezifische Encoder-Modell eine signifikant schlechtere Leistung als die anderen beiden LLM-basierten Verfahren. Im Rahmen des Methodenvergleichs lassen sich ebenfalls kaum signifikante Unterschiede ausmachen. Zumindest deskriptiv lagen das aufgabenspezifische Encoder-Modell und das universelle Decoder-Modell aber oberhalb der anderen AIA-Verfahren.
Ergänzende Validierung
Hier finden Sie außerdem eine umfängliche Validierung der Klassifikationen des kategoriespezifischen Encoder-Modells. Wir vergleichen dabei das Verfahren mit Kürzung langer Texte (also quasi “off the shelf”, wie im Paper berichtet) mit der komplexeren Anwendung inkl. Preprocessing bzw. Aufteilung langer Texte (siehe unterschiedliche Verfahren hier).
Literatur
Krippendorff, K. (2004a). Content Analysis: An Introduction to Its Methodology (2nd edition). Sage Publ.
Krippendorff, K. (2004b). Reliability in Content Analysis: Some Common Misconceptions and Recommendations. Human Communication Research, 30(3), 411–433. https://doi.org/10.1111/j.1468-2958.2004.tb00738.x
Scharkow, M. (2012). Automatische Inhaltsanalyse und maschinelles Lernen. epubli.