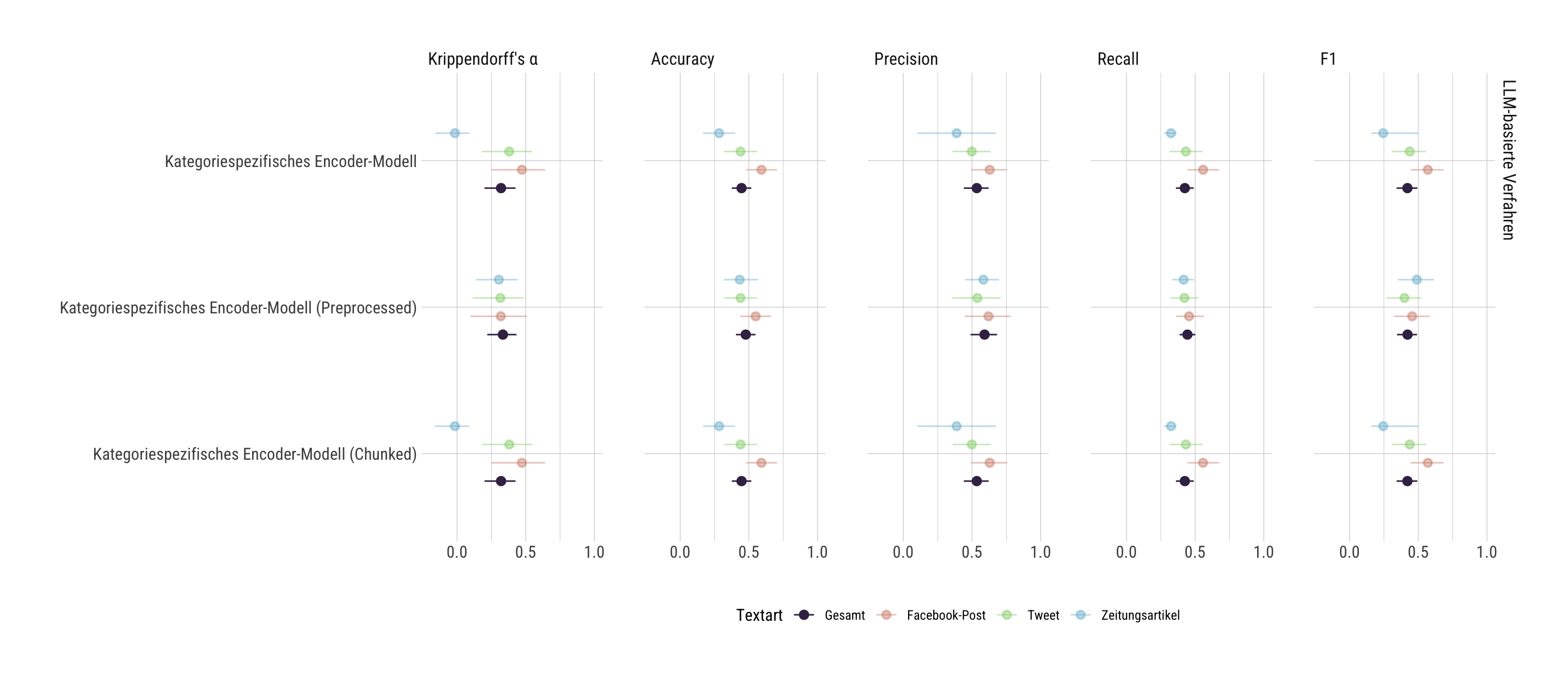
Um die Validität der verschiedenen Verfahren zu vergleichen, wurden die Codierergebnisse aller Verfahren mit der Codierung des Goldstandards verglichen.
Einlesen der Daten
Zunächst werden die Daten eingelesen und in ein einheitliches Format gebracht.
Import der notwendigen Bibliotheken für Datenverarbeitung, Visualisierung, Validierungsmetriken, Bootstrap-Sampling und Inter-Coder-Reliabilität.
2
Laden des Goldstandards und Konvertierung der numerischen Sentiment-Werte zu kategorialen Labels sowie Vereinheitlichung der Textarten.
3
Laden der kategoriespezifischen Encoder-Modell Ergebnisse und Konvertierung der Label-Namen zu einheitlichen deutschen Kategorien.
4
Laden der Chunked-Version des kategoriespezifischen Encoder-Modells und Konvertierung der Labels.
5
Laden der Preprocessed-Version des kategoriespezifischen Encoder-Modells und Konvertierung der Labels.
6
Zusammenführen aller Datensätze in einen einzigen Dataframe für die Validierung.
Validierung der Codierergebnisse
Anschließend werden die Validierungsmetriken für alle Verfahren berechnet. Dazu gehören Accuracy, Recall, Precision, F1-Score und Krippendorff’s Alpha. Die Metriken werden mittels Bootstrap-Sampling mit 2000 Wiederholungen geschätzt, um robuste Punktschätzer und 95%-Konfidenzintervalle zu erhalten. Dies wird für den gesamten Datensatz sowie separat für Facebook-Posts, Tweets und Zeitungsartikel durchgeführt.
Definition einer Hilfsfunktion zur Berechnung von Validierungsmetriken: Berechnung von Accuracy, Recall, Precision, F1-Score und Krippendorff’s Alpha für eine gegebene Variable gegen den Goldstandard.
2
Definition einer Bootstrap-Funktion für robuste Schätzung der Validierungsmetriken: Durchführung von Bootstrap-Sampling, Berechnung der Metriken für jede Stichprobe und alle Methoden, sowie Bestimmung von Punktschätzern und Konfidenzintervallen.
3
Bootstrap-Validierung für den gesamten Datensatz: Prüfung auf Existenz der Datei, falls nicht vorhanden Bootstrap mit 2000 Wiederholungen und Speicherung.
4
Bootstrap-Validierung spezifisch für Facebook-Posts: Filterung nach Facebook-Posts und separate Bootstrap-Validierung.
5
Bootstrap-Validierung spezifisch für Tweets: Filterung nach Tweets und separate Bootstrap-Validierung.
6
Bootstrap-Validierung spezifisch für Zeitungsartikel: Filterung nach Zeitungsartikeln und separate Bootstrap-Validierung.
Plot
Zuletzt wird ein Plot erstellt, der die Validierungsmetriken für alle Verfahren und Textarten visualisiert.
Vorbereitung der Plot-Daten: Laden aller Validierungsmetriken für verschiedene Textarten, Umbenennung der Methoden zu lesbaren Labels, Faktorisierung für richtige Reihenfolge und Kategorisierung in LLM-basierte vs. Vergleichsverfahren.
2
Erstellung des Validierungs-Plots: Umstrukturierung der Daten für ggplot, Umbenennung der Metriken, Erstellung eines Point-Range-Plots mit Konfidenzintervallen, farbkodiert nach Textarten und facettiert nach Verfahrenstyp und Metriken.